Top 5 Ways to Implement Real-Time Rich Text Editor (ranked by complexity)
We’ll go through the main approaches to implementing real-time rich text editors and try to assess their pros and cons.
Real-time experience becomes the new norm in building modern online tools.
Lots of collaboration tools implement real-time, including Almanac. This blog post is based on my research and experience building a rich doc editor that allows typing with other users in real-time, keeping docs’ history, forking docs, submitting changes, etc. Here is a list of all approaches we’re going to cover in this blog post:
0. Global Lock
1. Last Write Wins
2. Diff and Merge
3. Conflict-free Replicated Data Type (CRDT)
4. Pseudo Operational Transformation (OT)
5. Operational Transformation (OT)
I try to classify real-time problems into the following two categories:
- Real-time without conflicts (easy)

For example, real-time presence. These types of real-time features have many challenges to solve. But they can be solved by using some generic BaaS tools such as Pusher, Firebase, PubNub or open-source tools such as Phoenix Channels, Rails ActionCable, Node.js Socket.io that allow pushing updates to clients on certain changes.
- Real-time with conflicts (hard)

These types of real-time features are much harder to implement since multiple users can change the same data object, which may lead to race-conditions, conflicts, and data inconsistency.
0. Global Lock
If there is a way for multiple users to keep changing the doc, and data consistency is very important, then implementing some kind of lock could be the first solution to consider.

For example, if Alice changed “Foo” to “FooBar”, she first acquires a lock. Bob after that won’t be able to edit the doc.
It’s also possible to make the lock more granular. For example, implement a lock per element instead of the global doc lock.
Pros:
- The easiest to implement compared to other approaches.
Cons:
- Doesn’t actually enable real-time text editing, it prevents it :)
- Hard to deal with properly acquiring and releasing locks.
- May cause deadlocks similarly to a Mutex, for example.
1. Last Write Wins
This approach allows the implementation of some basic real-time text editing. If multiple users change the same doc at the same, the last user who made changes (e.g., the last changes received by the server) overrides all other users’ changes.

One strategy to reduce the number of conflicts could be to split the doc into many smaller fragments. Then use the “last write wins” approach only on each fragment instead of the whole doc.
Notion implements the “last write wins” approach that works fine enough in most cases.
Pros:
- The easiest to implement approach that enables real-time.
Cons:
- Overrides the user’s changes if multiple users edit the same element.
- Bad UX, as it may look that somebody deleted the user’s recent changes.
- Hard to maintain users’ local text cursor/selection positions.
2. Diff and Merge
The idea with this approach is to find the difference between the users’ changes and then try to merge them to avoid any data loss.
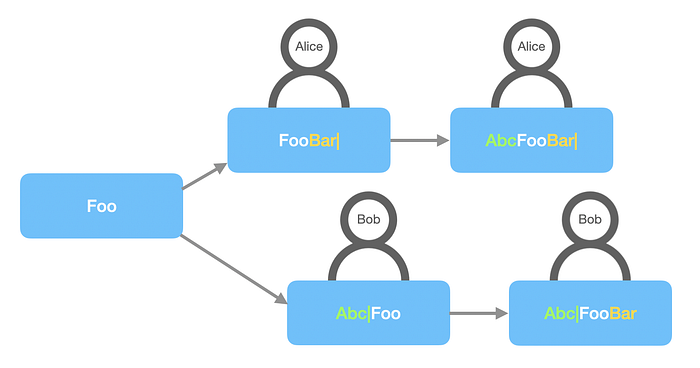
The initial Google Docs version used the “diff and merge” approach until it was rewritten by using operational transformation (OT).
One disadvantage is that it’s sometimes impossible to properly merge conflicting changes. For example, Alice added a character “i” to have “Foio” and Bob made the whole word bold “Foo”. Here it’s hard to tell exactly what’s going to happen, whether we should make the added character bold “Foio” or keep it not bold “Foio” or merge everything “FoioFoo”.
That’s why Git, for example, delegates resolving some conflicts to developers, as there is not enough context for it to know what the expected outcome is.
Pros:
- Great for merging changes made offline or asynchronously (like Git).
Cons:
- It’s not always possible to diff and merge changes correctly. Requires users’ input that might be frustrating if that happens very often.
- Hard to maintain users’ local text cursor/selection positions.
3. Conflict-free Replicated Data Type (CRDT)
CRDT is a relatively new concept that was created to solve some problems in distributed computing. It is used for building various types of distributed systems. For example, databases such as Redis Enterprise or Riak, cross node syncing in Elixir Phoenix, building privacy-centric alternatives to Zoom or YouTube with GUN.
Since real-time doc editing usually represents a distributed system with multiple clients and servers, it also makes sense to use this approach for building a real-time text editor.
Apple Notes app uses CRDT for syncing offline edits between devices.
The basic idea behind CRDT is to use some data types that make resolving conflicts extremely simple. To achieve this, operations on these data types should satisfy the following mathematical properties:
- Commutativeness, changing the order shouldn’t change the result. I.e. the order doesn’t matter.
- Idempotence, applying the same change multiple times produces the same result as it was applied only once.
When building a text editor, it is possible to split the content into separate characters and make sure that each of them has a unique ID. With these IDs, we can now correctly identify characters’ positions in the text.
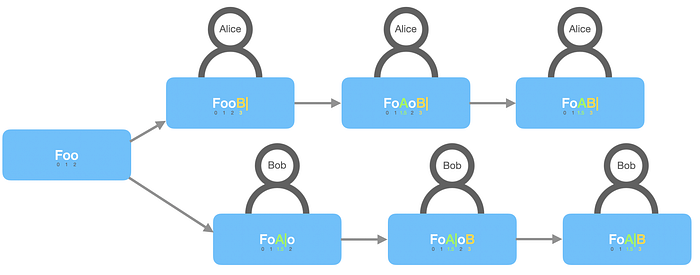
For example:
- Alice added “B” with ID 3.
- Bob added “A” between ID 1 and ID 2 with ID 1.5 (fractional index).
- Alice deleted “o” with ID 2.
- Bob deleted “o” with ID 2.
Now, if we change the order of these operations, the result will be still the same (commutativeness). And when both Alice and Bob deleted “o”, it works the same way as only one of them did that (idempotence).
Pros:
- Great for peer-to-peer communication in distributed systems, doesn’t require a central server.
- Relatively simple to reason about and easy to implement.
- Text cursor/selection positions are simpler to implement by using unique IDs. But it has to be implemented on a separate layer.
- There are a few useful open-source tools such as Yjs, Automerge, GUN.
- Can work offline.
Cons:
- Requires using specific data structures. If you already have a rich text editor with docs in the DB, it may mean a complete rewrite.
- Doesn’t play well if you want to have your server to be a single source of truth. Usually, your server becomes just one of the P2P nodes and may not have the latest data.
- Since it’s a relatively new approach, it’s not used very often for building real-time text editors, especially rich text editors beyond plain text. You’d need to read some research papers. For example, CRDT with JSON, CRDT with extensible data types, etc.
- CRDT simplifies conflict resolution, but it sacrifices intention-preservation. For example, Alice wanted to replace “F” in “Foo” with “W” to have “Woo”. Bob wanted to replace “Foo” with “Bar”. CRDT will split these replace operations into simple delete + add. Alice and Bob wanted to change “Foo” to have another word, but they’ll end up with something like “WBar” instead.
4. Pseudo Operational Transformation (OT)
Operational Transformation is one of the most popular approaches for building real-time rich text editors that was first researched in the 20th century.
There is no single conventional way to implement both CRDT and OT.
Figma, for example, implements real-time design collaboration by using Pseudo CRDT. In the same way, ProseMirror, a very popular framework for building rich text editors, implements Pseudo OT (I call it that way).
Let’s try to break down the following example when both Alice and Bob loaded the same doc with version V1 that contains “Foo”:
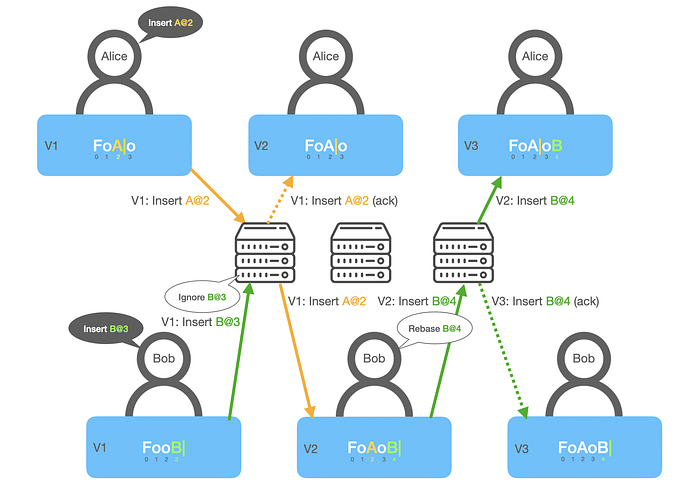
- Alice makes an operation (step in ProseMirror) that says Insert “A” at position #2. Sends a request with V1 to the central server. Bumps her version of the doc to V2.
- Bob makes another operation that says Insert “B” at position #3. Sends a request with V1 to the central server. Bumps his version of the doc to V2.
- The server receives Alice’s operation with V1 first and persists it. After that, it broadcasts this operation to all the clients.
- The server receives Bob’s operation with V1. Since the server already saw an operation with V1, it ignores it, assuming that Bob will resend this operation again.
- Alice receives her operation as an acknowledgment.
- Bob receives and applies Alice’s operation that inserted 1 character. Then Bob performs OT (rebasing in ProseMirror) on his operation Insert “B” at position #3 that becomes Insert “B” at position #4 (shifted by 1 character). After that, he tries to resend his operation again, now with V2. Bumps his version of the doc to V3.
- The server receives Bob’s operation Insert “B” at position #4 with V2. This version doesn’t conflict with previously persisted operations. So the server saves it and broadcasts it to all the clients.
- Bob receives his recent operation as an acknowledgment.
- Alice receives Bob’s operation and applies it. After that, she bumps her version of their docs to V3. Phew!
The New York Times uses ProseMirror with Pseudo OT for collaborative editing.
Pros:
- If you already use a text editor like ProseMirror, this approach feels very natural, and it comes with tools that already work with the existing data structures (steps) and implement OT (rebasing).
- It works great in the client/server architecture with a central DB. Clients can continue changing the doc with an optimistic UI and a local buffer with unconfirmed operations.
- The server doesn’t have to know anything about OT. It just stores operations (event sourcing), broadcasts or rejects some of them if there is a conflicting version.
- Unlike CRDT, it preserves users’ intentions. E.g. “replace a character” instead of “delete + add a character” or “make a character bold” instead of “delete and add a bold character”.
- It automatically keeps track of text cursor/selection positions.
Cons:
- It’s not conventional OT. It increases coupling to ProseMirror and its internal implementation (along with its limitations).
- Since OT happens only on the client-side, it may cause a network messages overhead when trying to transform and resubmit changes from the clients. The more clients are editing the same doc, the more conflicting changes and more messages are being sent back and forth. This may lead to broadcasting delays.
- Rebasing changes (aka local changes transformation only, not remote) may sometimes fail and lead to dropping some changes. For example, Alice deleted the word “Foo”. When Bob tries to append “Bar” to “Foo”, his operation may fail as it’s not rebasable against Alice’s deletion. I.e. “Bob” may lose his “Bar” change.
- This approach is not suitable for long offline sessions.
5. Operational Transformation
This is a conventional approach used by most popular real-time text editors such as Google Docs, Dropbox Paper, Etherpad and many others.
It took 2 years to write Google Wave’s whitepaper that later allowed Google to build Google Docs with the client/server communication architecture.
It’s similar to the Pseudo OT approach. The major difference though is that the server can also apply transformations, so there is no need to force clients to resolve conflicts by applying transformations and resubmitting the changes.
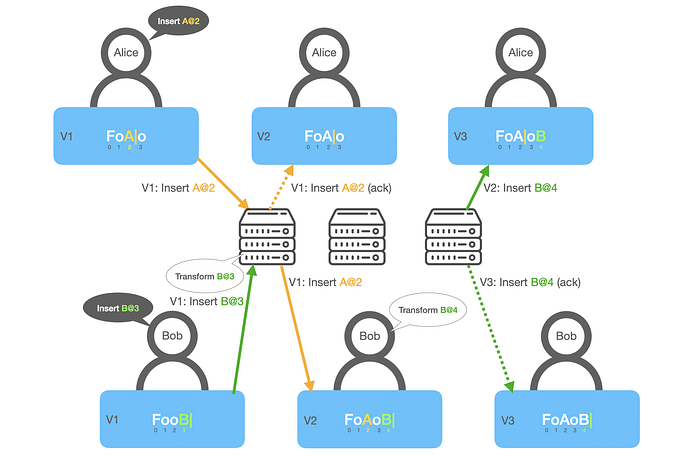
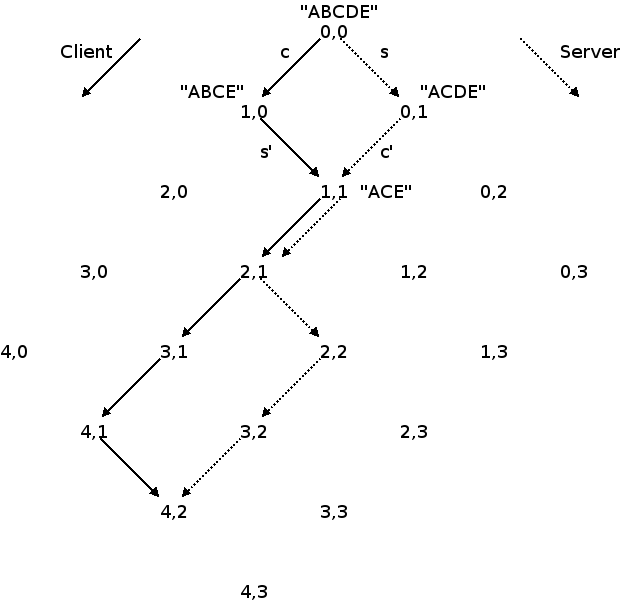
Imagine Alice and Bob loaded the same doc with version V1 that contains “Foo”:
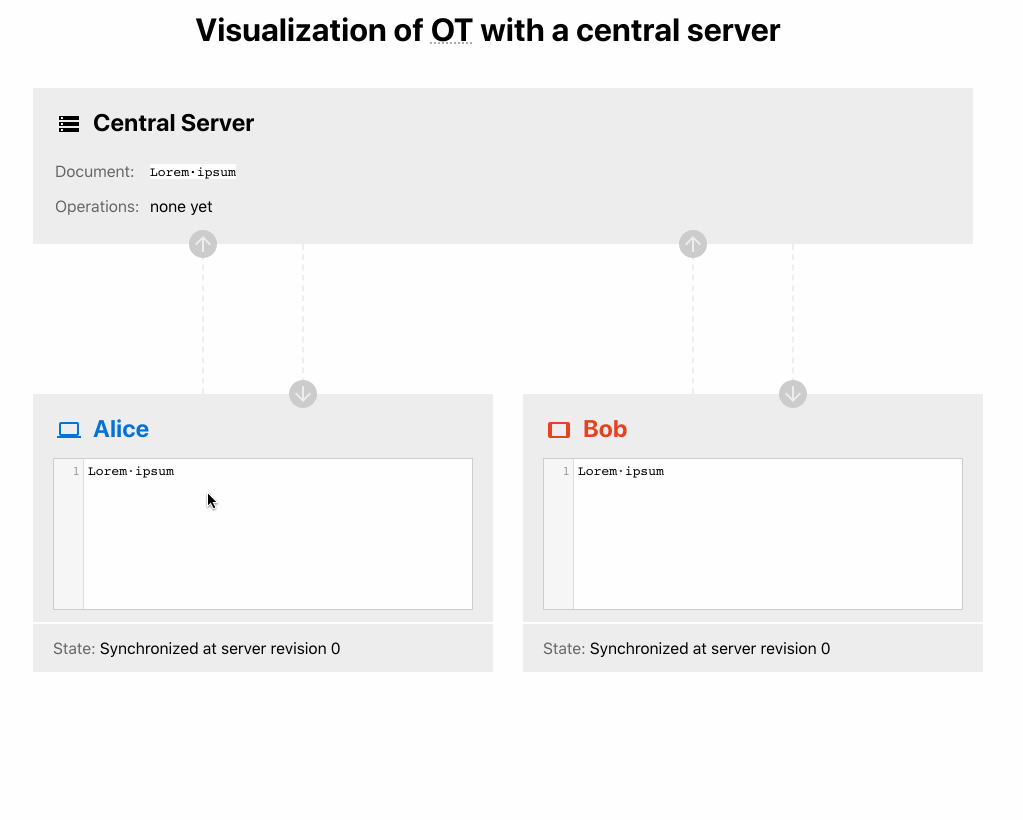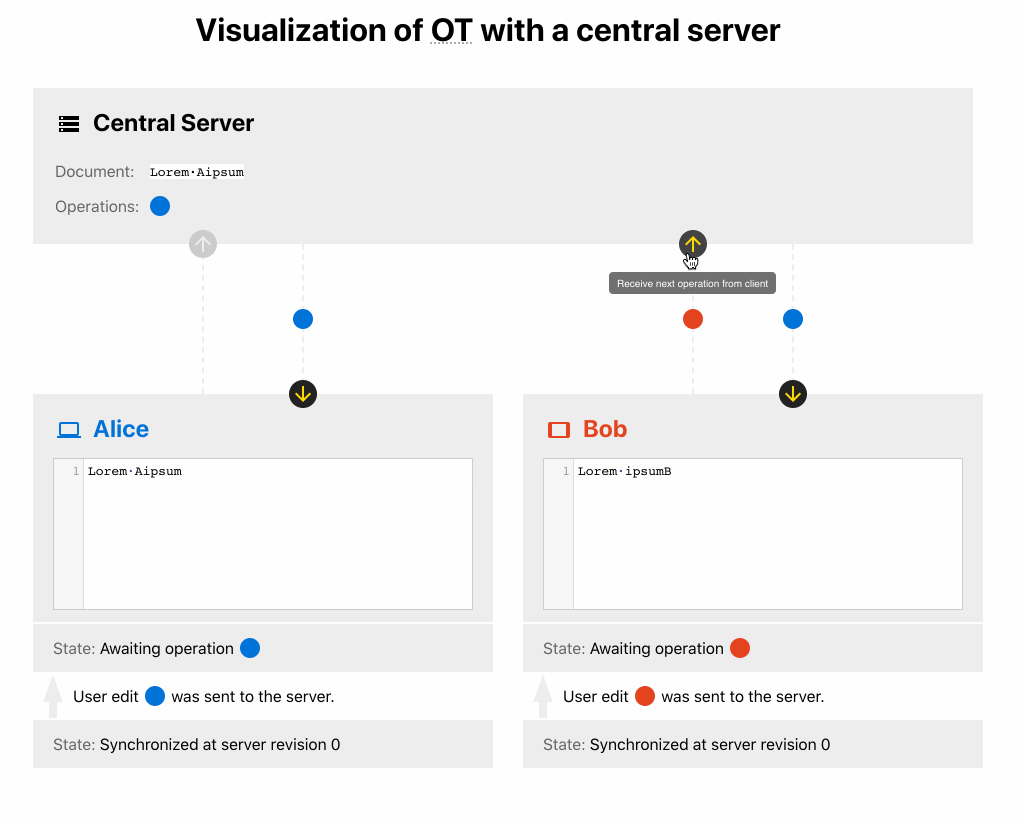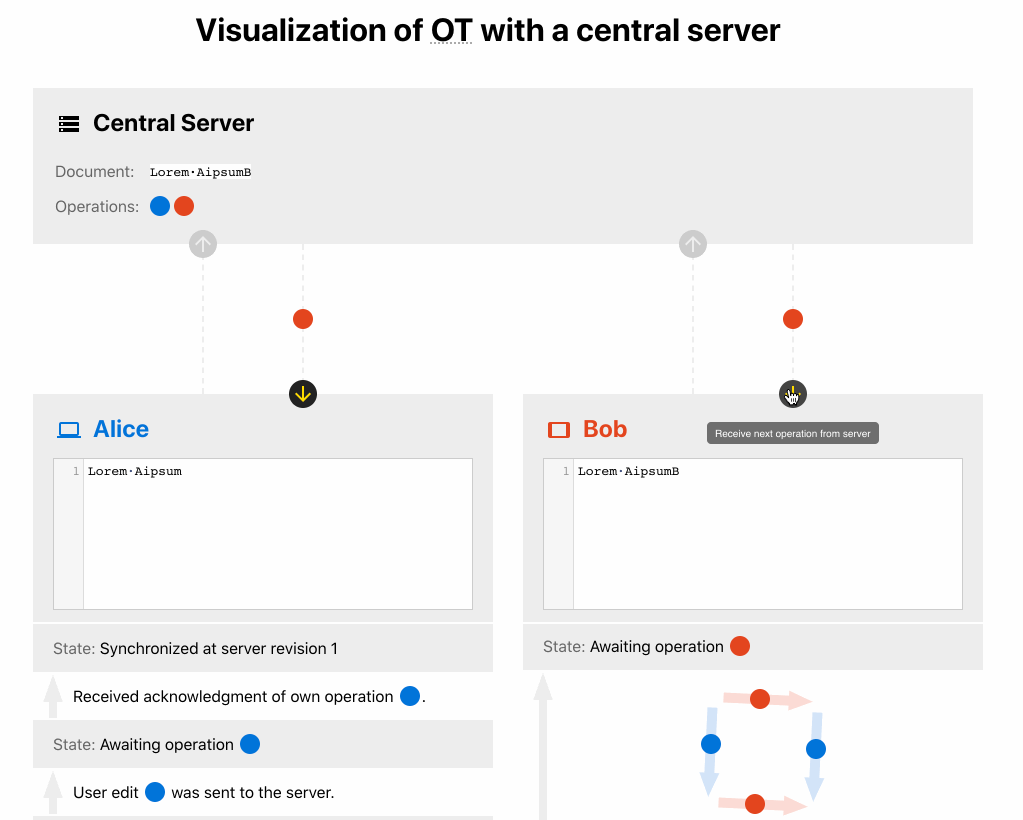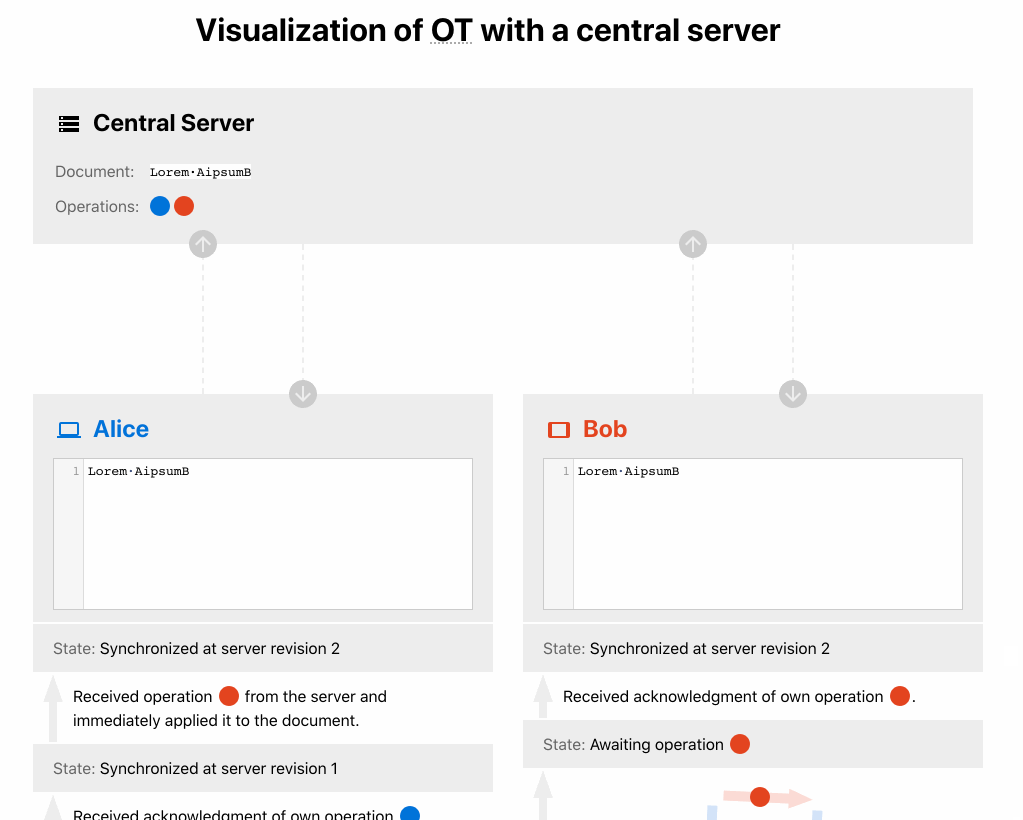
- Alice makes an operation that says Insert “A” at position #2. Sends a request with V1 to the central server. Bumps her version of the doc to V2.
- Bob makes another operation that says Insert “B” at position #3. Sends a request with V1 to the central server. Bumps his version of the doc to V2.
- The server receives Alice’s operation with V1 first and persists it. After that, it broadcasts this operation to all the clients.
- The server receives Bob’s operation with V1. Since the server already saw an operation with V1, it transforms Bob’s operation to Insert “B” at position #4 and save it. After that, it’ll broadcast this operation to all other clients.
- Alice receives her operation as an acknowledgment.
- Bob receives and applies Alice’s operation that inserts 1 character. Then Bob locally also performs OT to Insert “B” at position #4. Bumps his version of the doc to V3.
- Alice receives Bob’s operation and applies it. After that, she bumps her version of their docs to V3.
- Bob receives his operation acknowledgment.
It means that clients send their changes only once and wait for acknowledgment from the server. The server performs transformations when there are conflicts and always accepts any new operations.
It’s all possible only with transformations that can be applied by both the client and the server to get to the same convergent state, no matter when they received the other operations. These states are called state spaces because they contain different paths of operational transformation.
Pros:
- The battle-tested and historically one of the most popular approaches for building real-time rich text editors.
- It works great in the client/server architecture with a central DB. The server uses only a single state space as the source of truth. Clients wait for acknowledgment to make sure that they stay on the same server’s OT path.
- Unlike the Pseudo OT, there are no extra back-and-forth messages sent between the clients and the server.
- Unlike CRDT, OT can ensure that the effect of executing an operation on any document state is the same as the intention of the operation (intention preservation).
- There are a few helpful open-source tools such as quill-delta, ottypes, sharedb, etc.
- It allows keeping track of text cursor/selection positions.
- Can work offline.
Cons:
- The server should also know how to perform operational transformation.
- Depending on your editor, it might require adding an extra layer on top. For example, to map data structures from ProseMirror to OT.
- Relatively hard to implement. Doesn’t provide 100% correctness. Similarly to CRDT, requires deep understanding of the theory behind it.
Conclusion
We just covered the tip of the iceberg. To build a real-time rich text editor, it’s also necessary to solve a lot of extra problems and find answers to questions about real-time communication and infrastructure, implementing shared or local undo/redo, keeping track of local or remote text cursors/selections, versioning, etc.
As a general rule of thumb:
- If you need to build a basic real-time text editor, you might be fine with implementing a “lock” or the “last write wins” strategy.
- For large text changes made asynchronously or offline, the best solution could be to implement the “diff and merge” strategy.
- If you build a text editor that is meant to be used P2P, then you probably want to choose CRDT.
- If you use ProseMirror, then you might consider using its prosemirror-collab plugin.
- If you know that real-time rich text editing will be your primary feature, then you’d probably want to double down and use OT.
Such terms as CRDT and OT sound like some kinds of black magic. I hope that more open-source tools will allow to hide some complexity, lower the entry barrier, and democratize access to building real-time rich text editors in the future. And I hope that those who are familiar with these approaches will continue spreading their knowledge and leave their feedback. Thank you.
