PostgreSQL, one of the most popular databases, was named DBMS of the Year 2023 by DB-Engines Ranking and is used more than any other database among startups according to HN Hiring Trends.

The SQL standard has included features related to temporal databases since 2011, which allow storing data changes over time rather than just the current data state. However, relational databases don’t completely follow the standards. In the case of PostgreSQL, it doesn’t support these features, even though there has been a submitted patch with some discussions.
There are PostgreSQL extensions like periods and temporal_tables that add support for temporal tables. Unfortunately, cloud providers such as AWS, Azure, and GCP don’t allow running custom C extensions with managed databases.
Let’s explore five alternative methods of data change tracking in PostgreSQL available to us in 2024.
Triggers and Audit Table

PostgreSQL allows adding triggers with custom procedural SQL code performed on row changes with INSERT, UPDATE, and DELETE queries. The official PostgreSQL wiki describes a generic audit trigger function. Let’s have a quick look at a simplified example.
First, create a table called logged_actions in a separate schema called audit:
CREATE schema audit;
CREATE TABLE audit.logged_actions (
schema_name TEXT NOT NULL,
table_name TEXT NOT NULL,
user_name TEXT,
action_tstamp TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT current_timestamp,
action TEXT NOT NULL CHECK (action IN ('I','D','U')),
original_data TEXT,
new_data TEXT,
query TEXT
);Next, create a function to insert audit records and establish a trigger on a table you wish to track, such as my_table:
CREATE OR REPLACE FUNCTION audit.if_modified_func() RETURNS TRIGGER AS $body$
BEGIN
IF (TG_OP = 'UPDATE') THEN
INSERT INTO audit.logged_actions (schema_name,table_name,user_name,action,original_data,new_data,query)
VALUES (TG_TABLE_SCHEMA::TEXT,TG_TABLE_NAME::TEXT,session_user::TEXT,substring(TG_OP,1,1),ROW(OLD.*),ROW(NEW.*),current_query());
RETURN NEW;
elsif (TG_OP = 'DELETE') THEN
INSERT INTO audit.logged_actions (schema_name,table_name,user_name,action,original_data,query)
VALUES (TG_TABLE_SCHEMA::TEXT,TG_TABLE_NAME::TEXT,session_user::TEXT,substring(TG_OP,1,1),ROW(OLD.*),current_query());
RETURN OLD;
elsif (TG_OP = 'INSERT') THEN
INSERT INTO audit.logged_actions (schema_name,table_name,user_name,action,new_data,query)
VALUES (TG_TABLE_SCHEMA::TEXT,TG_TABLE_NAME::TEXT,session_user::TEXT,substring(TG_OP,1,1),ROW(NEW.*),current_query());
RETURN NEW;
END IF;
END;
$body$
LANGUAGE plpgsql;
CREATE TRIGGER my_table_if_modified_trigger
AFTER INSERT OR UPDATE OR DELETE ON my_table
FOR EACH ROW EXECUTE PROCEDURE if_modified_func();Once it’s done, row changes made in my_table will create records in audit.logged_actions:
INSERT INTO my_table(x,y) VALUES (1, 2);
SELECT * FROM audit.logged_actions;If you want to further improve this solution by using JSONB columns instead of TEXT, ignoring changes in certain columns, pausing auditing a table, and so on, check out the SQL example in this audit-trigger repo and its forks.
Another alternative is the temporal_tables implementation written by using triggers. The main difference is that it stores records in a separate table with a time range during which a version was valid, not just an initial timestamp when a change was recorded. This makes it easier to perform time travel queries by selecting records that were valid at a specific point in time.
Downsides
- Performance. Triggers add performance overhead by inserting additional records synchronously on every
INSERT,UPDATE, andDELETEoperation. - Security. Anyone with superuser access can modify the triggers and make unnoticed data changes. It is also recommended to make sure that records in the audit table cannot be modified or removed.
- Maintenance. Managing complex triggers across many constantly changing tables can become cumbersome. Making a small mistake in an SQL script can break queries or data change tracking functionality.
Triggers and Notify/Listen

This approach is similar to the previous one but instead of writing data changes in the audit table directly, we pass them through a pub/sub mechanism through a trigger to another system dedicated to reading and storing these data changes:
CREATE OR REPLACE FUNCTION if_modified_func() RETURNS TRIGGER AS $body$
BEGIN
IF (TG_OP = 'UPDATE') THEN
PEFORM pg_notify('data_changes', json_build_object(
'schema_name', TG_TABLE_SCHEMA::TEXT,
'table_name', TG_TABLE_NAME::TEXT,
'user_name', session_user::TEXT,
'action', substring(TG_OP,1,1),
'original_data', jsonb_build(OLD),
'new_data', jsonb_build(NEW)
)::TEXT);
RETURN NEW;
elsif (TG_OP = 'DELETE') THEN
PEFORM pg_notify('data_changes', json_build_object(
'schema_name', TG_TABLE_SCHEMA::TEXT,
'table_name', TG_TABLE_NAME::TEXT,
'user_name', session_user::TEXT,
'action', substring(TG_OP,1,1),
'original_data', jsonb_build(OLD)
)::TEXT);
RETURN OLD;
elsif (TG_OP = 'INSERT') THEN
PEFORM pg_notify('data_changes', json_build_object(
'schema_name', TG_TABLE_SCHEMA::TEXT,
'table_name', TG_TABLE_NAME::TEXT,
'user_name', session_user::TEXT,
'action', substring(TG_OP,1,1),
'new_data', jsonb_build(NEW)
)::TEXT);
RETURN NEW;
END IF;
END;
$body$
LANGUAGE plpgsql;
CREATE TRIGGER my_table_if_modified_trigger
AFTER INSERT OR UPDATE OR DELETE ON my_table
FOR EACH ROW EXECUTE PROCEDURE if_modified_func();Now it’s possible to run a separate process running as a worker that listens to messages containing data changes and stores them separately:
LISTEN data_changes;Downsides
- “At most once” delivery. Listen/notify notifications are not persisted meaning if a listener disconnects, it may miss updates that happened before it reconnected again.
- Payload size limit. Listen/notify messages have a maximum payload size of 8000 bytes by default. For larger payloads, it is recommended to store them in the DB audit table and send only references of the records.
- Debugging. Troubleshooting issues related to triggers and listen/notify in a production environment can be challenging due to their asynchronous and distributed nature.
Application-Level Tracking
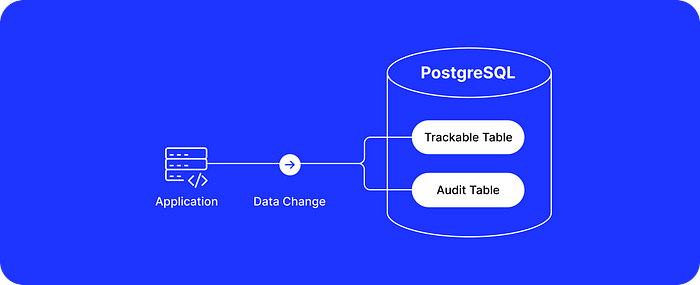
If you have control over the codebase that connects and makes data changes in a PostgreSQL database, then one of the following options is also available to you:
- Manually record all data changes when issuing
INSERT,UPDATE, andDELETEqueries - Use existing open-source libraries that integrate with popular ORMs
For example, there is paper_trail for Ruby on Rails with ActiveRecord and django-simple-history for Django. At a high level, they use callbacks or middlewares to insert additional records into an audit table. Here is a simplified example written in Ruby:
class User < ApplicationRecord
after_commit :track_data_changes
private
def track_data_changes
AuditRecord.create!(auditable: self, changes: changes)
end
endOn the application level, Event Sourcing can also be implemented with an append-only log as the source of truth. But it’s a separate, big, and exciting topic that deserves a separate blog post.
Downsides
- Reliability. Application-level data change tracking is not as accurate as database-level change tracking. For example, data changes made outside an app will not be tracked, developers may accidentally skip callbacks, or there could be data inconsistencies if a query changing the data has succeeded but a query inserting an audit record failed.
- Performance. Manually capturing changes and inserting them in the database via callbacks leads to both runtime application and database overhead.
- Scalability. These audit tables are usually stored in the same database and can quickly become unmanageable, which can require separating the storage, implementing declarative partitioning, and continuous archiving.
Change Data Capture
Change Data Capture (CDC) is a pattern of identifying and capturing changes made to data in a database and sending those changes to a downstream system. Most often it is used for ETL to send data to a data warehouse for analytical purposes.
There are multiple approaches to implementing CDC. One of them, which doesn’t intersect with what we have already discussed, is a log-based CDC. With PostgreSQL, it is possible to connect to the Write-Ahead Log (WAL) that is used for data durability, recovery, and replication to other instances.

PostgreSQL supports two types of replications: physical replication and logical replication. The latter allows decoding WAL changes on a row level and filtering them out, for example, by table name. This is exactly what we need to implement data change tracking with CDC.
Here are the basic steps necessary for retrieving data changes by using logical replication:
1. Set wal_level to logical in postgresql.conf and restart the database.
2. Create a publication like a “pub/sub channel” for receiving data changes:
CREATE PUBLICATION my_publication FOR ALL TABLES;3. Create a logical replication slot like a “cursor position” in the WAL:
SELECT * FROM pg_create_logical_replication_slot('my_replication_slot', 'wal2json')4. Fetch the latest unread changes:
SELECT * FROM pg_logical_slot_get_changes('my_replication_slot', NULL, NULL)To implement log-based CDC with PostgreSQL, I would recommend using the existing open-source solutions. The most popular one is Debezium.
Downsides
- Limited context. PostgreSQL WAL contains only low-level information about row changes and doesn’t include information about an SQL query that triggered the change, information about a user, or any application-specific context.
- Complexity. Implementing CDC adds a lot of system complexity. This involves running a server that connects to PostgreSQL as a replica, consumes data changes, and stores them somewhere.
- Tuning. Running it in a production environment may require a deeper understanding of PostgreSQL internals and properly configuring the system. For example, periodically flushing the position for a replication slot to reclaim WAL disk space.
Integrated Change Data Capture
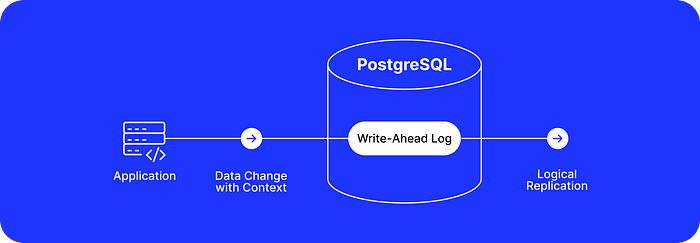
To overcome the challenge of limited information about data changes stored in the WAL, we can use a clever approach of passing additional context to the WAL directly.
Here is a simple example of passing additional context on row changes:
CREATE OR REPLACE FUNCTION if_modified_func() RETURNS TRIGGER AS $body$
BEGIN
PERFORM pg_logical_emit_message(true, 'my_message', 'ADDITIONAL_CONTEXT');
IF (TG_OP = 'DELETE') THEN
RETURN OLD;
ELSE
RETURN NEW;
END IF;
END;
$body$
LANGUAGE plpgsql;
CREATE TRIGGER my_table_if_modified_trigger
AFTER INSERT OR UPDATE OR DELETE ON my_table
FOR EACH ROW EXECUTE PROCEDURE if_modified_func();Notice the pg_logical_emit_message function that was added to PostgreSQL as an internal function for plugins. It allows namespacing and emitting messages that will be stored in the WAL. Reading these messages became possible with the standard logical decoding plugin pgoutput since PostgreSQL v14.
There is an open-source project called Bemi which allows tracking not only low-level data changes but also reading any custom context with CDC and stitching everything together. Full disclaimer, I’m one of the core contributors.
For example, it can integrate with popular ORMs and adapters to pass application-specific context with all data changes:
import { setContext } from "@bemi-db/prisma";
import express, { Request } from "express";
const app = express();
app.use(
// Customizable context
setContext((req: Request) => ({
userId: req.user?.id,
endpoint: req.url,
params: req.body,
}))
);Downsides
- Complexity and tuning related to implementing CDC.
If you need a ready-to-use cloud solution that can be integrated and connected to PostgreSQL in a few minutes, check out bemi.io.
Conclusion
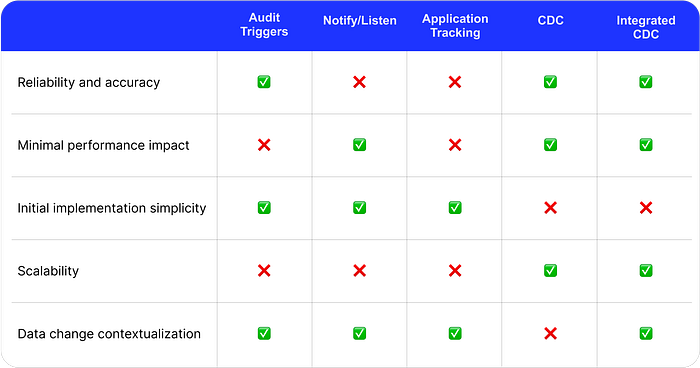
- If you need basic data change tracking, triggers with an audit table are a great initial solution.
- Triggers with listen/notify are a good option for simple testing in a development environment.
- If you value application-specific context (information about a user, API endpoint, etc.) over reliability, you can use application-level tracking.
- Change Data Capture is a good option if you prioritize reliability and scalability as a unified solution that can be reused, for example, across many databases.
- Finally, integrated Change Data Capture is your best bet if you need a robust data change tracking system that can also be integrated into your application. Go with bemi.io if you need a cloud-managed solution.
